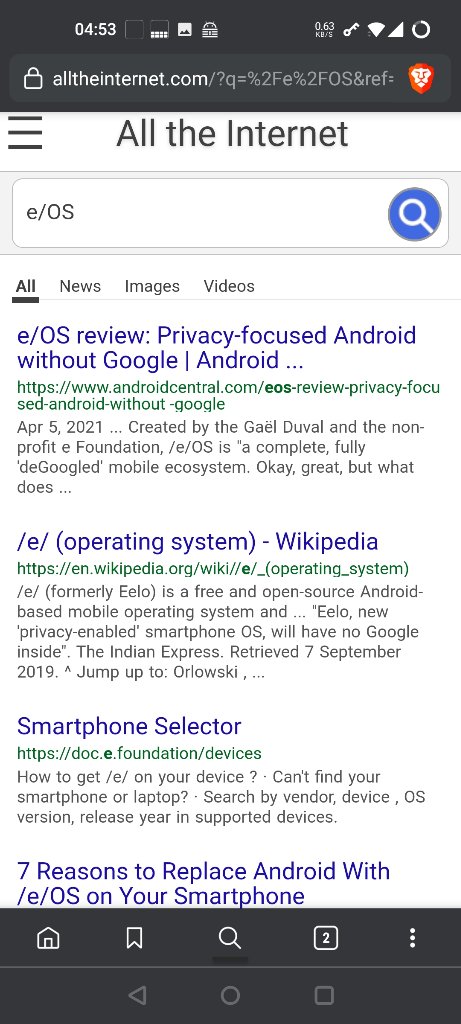
As of late I’ve been using All The Internet as my search engine. Mostly because it’s just clean looking on mobile (though not so much in Privacy Browser even with Wide Viewport turned off).
Only recently discovered it even though it’s been around for years.
Saw this article comparing it with DuckDuckGo. As is the case with most articles, take it with a grain of salt.
Umm, it’s just a.search engine. Go to https://www.alltheinternet.com/ and search like normal.
I do believe that once you do that it’ll show up as a choice for search engine in chromium-based browsers settings (Recently visited).
For others where you can specify a custom search engine, try this maybe…
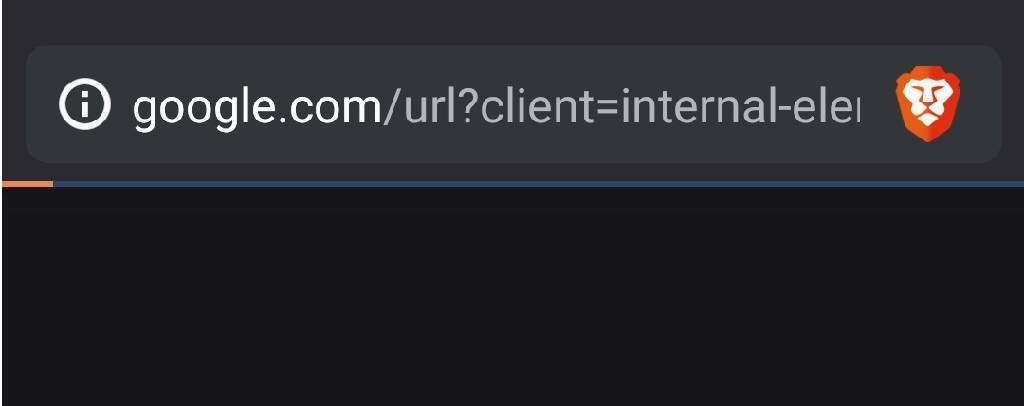
@marcdw Ive been using All The Internet. Question, when I search and the engine returns results > click on one of the results I see “g00gle.com…” in the domain window temporarily till the site I clicked on in the search results loads. Can you decode what is going on in the backend? Is the engine crawling G00gle’s results then pulling them through their frontend? (similar to say NewPipe pulling YouT#*e’s results?) Is G getting any metadata on me from this? If not how do you verify? Thanks.
EDIT: Here I was able to quickly capture a print screen of it
Alltheinternet is a metasearch engine. This means they aggregate results of search queries from various sources (incl. Bing, Google, …). At the end it is compareable to spot from /e/, which is based on searx. As such the two later are very configurable and may yield the same/similar results. You can adjust which sources are used. The number of sources is growing in searx/spot. Searx has the benefit that you can decide which instances (decentralized in contrast to alltheinternet) you want to use. You could even use your own.
Got it, so if I understand right the aggregate search results are resolved away from the end user (us) and the search engines are unable to see through All The Internet’s UI/webpage to us on the other side? It seems odd to me that I am seeing G**gle.com in the domain search bar as previously described above.
Methinks this is the idea. However, I haven’t found an analysis of this search engine. Moreover, they need some infrastructure. AWS, Google and MS are natural choices here. Guess there is someone more knowledgeable in this forum.
You can use trackercontrol. It appears indeed that they ping google and some others directly.
I don’t know exactly what that Google thing is but maybe we see a glimpse of some kind of sanitizing of the Google search results.
Not sure what else is in that line. “…client=internal-element[something_or_other]”.
Was thinking something along the lines of how Privacy Browser strips tracking items from URLs. But really I don’t know.

 .
.