We are actually performing maintenance operations on our ecloud.global site. Sorry for the inconvenience.
This was normally announced on our Telegram announcement channel. If not, this is a problem and we are fixing it.
Please be patient.
The migration went fine but ecloud.global still struggles to handle heavy load so access is disabled for now, until we find the root cause of the issue
first of all apologies for all the troubles this situation has caused you, and for the lack of update on the status yesterday. Here’s where we stand and our options to get the service back up as quickly as possible (which of course was always our priority).
We’ve migrated to a new hosting provider with a more distributed architecture.
Your data is safe and our new storage system is working with no issues.
E-mail has been moved to its own server and it’s working well. You can use any client except the web client (ecloud.global / e.mail).
We’ve also taken the chance to upgrade Nextcloud to version 18 and other goodies like a VPN that protects communication between all new servers. But this introduces some difficulties in simply restoring to the previous server; it’s not impossible but it is not simply a matter of switching the DNS back and copying the new files there.
With little load, the new infrastructure is responsive. It’s not “broken” in the functional sense. But with all traffic on, it’s CPU quickly becomes clogged.
Hardware-wise, the new nextcloud server is comparable to the old one, even has double the RAM. Same fine tuning, less services running… it should not perform like this. We fixed a few causes but it is still not responding well.
OK so from here, how do we plan to fix it?
We have changed the maintenance page to a blank page but your phone should not show any more error message while it’s down (only if we disable maintenance to check if our solutions are working).
We’ll keep working over the weekend so the service is fully restored at some point tomorrow, in the new infrastructure or the old one. Estimates are hard because of the huge number of files involved. For you to get an idea, a chown to fix file permissions can take from 40 minutes to 2h. Transferring between servers also isn’t limited by bandwidth.
We have a few options yet to run in the new architecture: our plan until last week was to have a redundant load-balanced nextcloud web server, and the node is there. The DB is also replicated. They can’t share storage for other reasons I can’t cover here and this means we can’t fully load balance. But we can use the DB in the secondary node to reduce the load of the primary, and maybe split some of the web traffic too, but we need to check that.
If that fails, we have 2 options: to use the previous server as nextcloud node but keep it in the new infrastructure with the VPN, or to fully revert to the previous configuration, except email maybe.
I’ll update on this thread when we have new information.
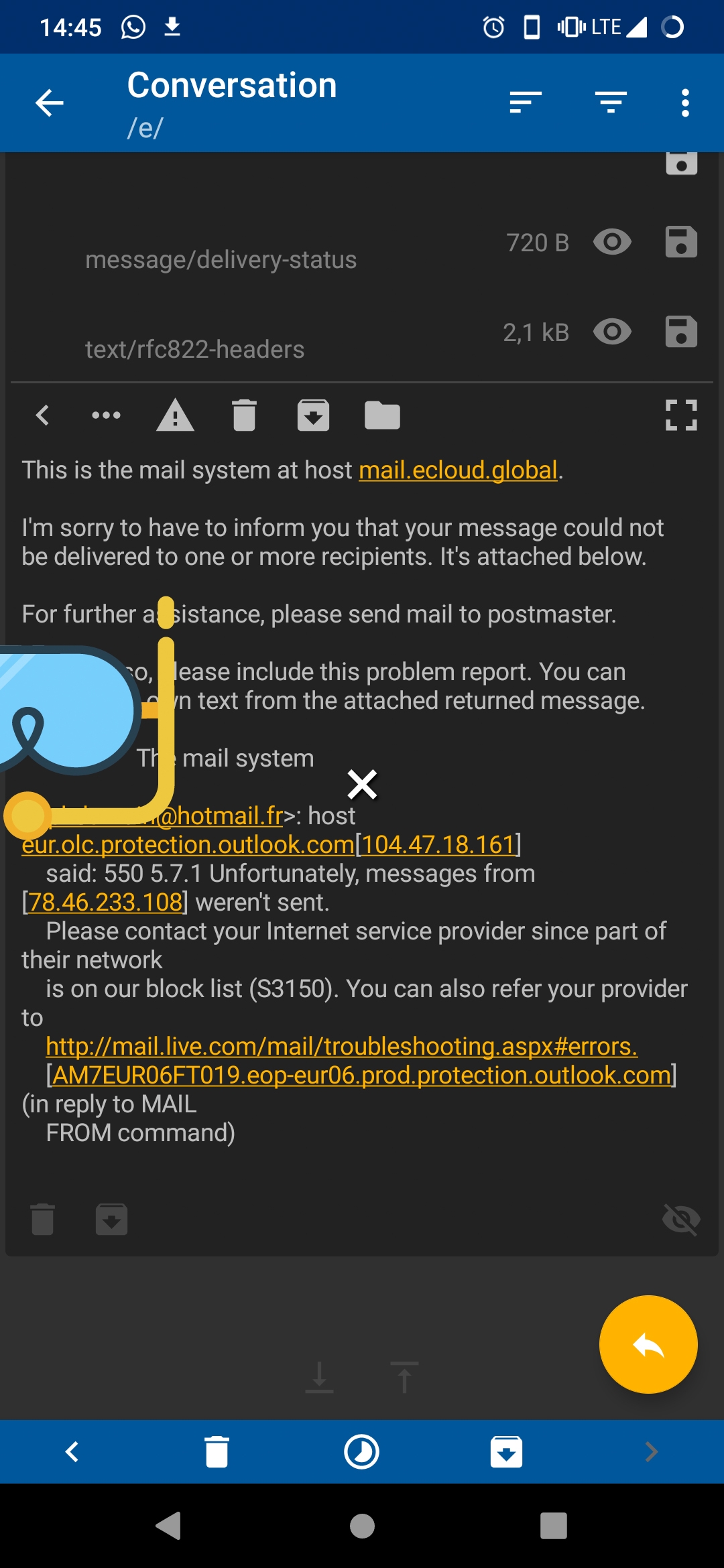
I can’t send email to hotmail since the migration because: “Please contact your Internet service provider since part of their network is on our block list (S3150)”.
Is this normal behaviour in the current situation?
The issue with MS servers not accepting emails from /e/ ID is unrelated to this migration. The team is also working on that issue separately. We will update on the resolutions as they come in.
I guess it’s been a long wait for everyone without news but I can assure we’ve been busy every minute. And as I explained before, time flies and delays pile up quickly.
So first of all, the bad news:
We are reverting to the previous server (V1 from now on)
Let me sum up what we did today:
We moved the DB to the secondary server and used the same image as in V1
We removed the load balancer and channeled all traffic to nginx, again as in V1
We played with different nginx configurations
Sadly, after all that, we didn’t see at all the behaviour we expected, CPU was still at 100% when traffic was on (the DB node was fine). But this setup gave us more information than previously and we were able to uncover a performance issue on the new storage system. Which means we have to revert for now…
The good news is, today the engineer in charge of storage found the way to further improve read/write speeds by a factor of 10, but it needs copying all data from scratch in a new volume (again, more time) and testing to ensure it performs well on all scenarios (e.g. power loss when the server is writing to the local cache). We will provide an update in the following weeks.
Thanks for your patience. I will provide one last update on this thread as soon as the service is restored on the V1 server. E-mail will be stopped a few minutes tonight tomorrow morning so we can sync it in a coherent state.
Thanks for all your work and effort providing us the best service !
Reverting is a hard decision to take … but the good one sometime. Have a good day
Céline
If anyone sends an email to the …@e.email account, will it be received and available after the migration, or will the sender receive a “service denial” message?